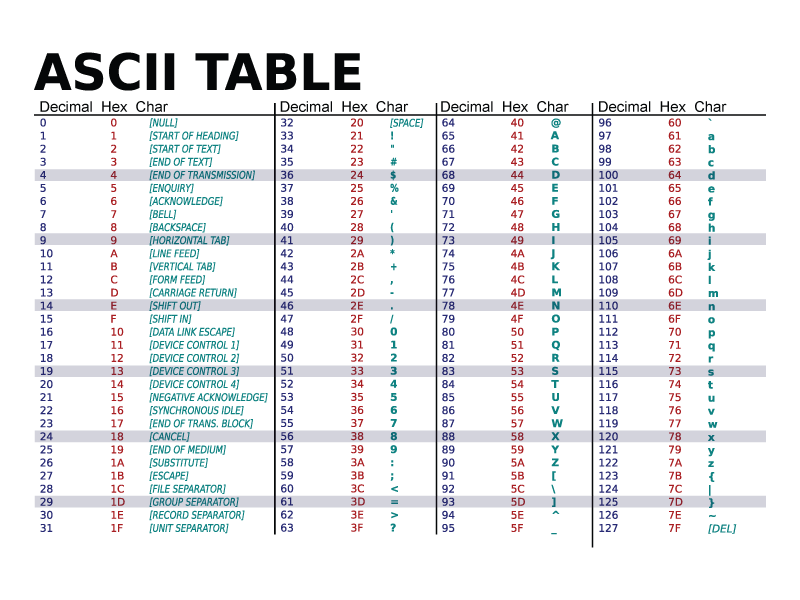
Codul ASCII
În orice sistem de calcul, datele – de orice tip – se memorează sub formă de numere. Mai mult, acestea se reprezintă în baza 2. În consecință, pentru a memora în calculator caractere este necesară utilizarea unei reprezentări a caracterelor prin numere. O astfel de reprezentare este Codul ASCII.
ASCII este o formă de reprezentare în calculator a caracterelor folosită în toate limbajele de programare studiate în liceu, alături eventual de alte reprezentări.
Codul ASCII standard codifică caracterele folosind 7 biți, astfel că permite codificarea a 27=128 caractere. Nu sunt prea multe! De fapt sunt codificate numai literele din alfabetul englez, cifrele de la 0 la 9, semnele de punctuație și operatorii, precum și alte simboluri. Lipsesc cu desăvârșire literele specifice altor alfabete latine (așa numite litere cu diacritice, precum ar fi ă Ă î Î â Â ș Ș ț Ț ş Ş Ţ ţ (observăm că sunt două feluri de Ș și doua feluri de Ţ, dar despre acest fapt vom discuta în alt articol ), precum și literele din alte alfabete: chirilic, ebraic, arab, chinez, etc. Pentru memorarea acestor litere se poate folosi codul ASCII Extins, sau codul UNICODE.
Prin codul ASCII, fiecărui caracter reprezentat în acest cod i se asociază un număr. Aceste numere (numite chiar coduri ASCII) se găsesc în intervalul 0 .. 127. Caracterele ASCII se împart în două categorii:
- caractere imprimabile – cele cu codurile ASCII în intervalul 32 126, inclusiv capetele: aici se regăsesc toate caracterele care au o reprezentare grafică bine determinată:
- literele mari: A ... Z,
- literele mici: a ... z,
- cifrele 0 .. 9,
- semnele de punctuaţie .,:;!?'"
- caractere ce reprezintă operaţii aritmetice sau de alt tip: + - / * <> = (){}[]
- alte caractere: ~`@#$%^&_\|
- caracterul spaţiu
- caracterele neimprimabile, sau de control – cu codurile 0 .. 31 și 127. Ele erau folosite mai demult pentru a controla transmiterea datelor. Caracterele neimprimabile nu au o reprezentare grafică bine determinată – în funcţie de sistemul operare folosit, reprezentările grafice ale acestor caractere pot fi foarte diferite, sau chiar să lipsească cu totul. Dintre aceste caractere amintim două, de o importanţă mai mare în limbajele de programare studiate:
- caracterul cu codul 0, numit și caracter nul, notat în C++ cu '\0' – reprezintă finalul unui șir de caractere în memorie
- caracterul cu codul 10, numit Line Feed, notat în C++ cu '\n' – produce trecerea la rând nou atunci când este afișat pe ecran sau într-un fișier.
Observaţii utile
- literele mari și literele mici sunt diferite – au coduri ASCII diferite
- codurile ASCII ale literelor mari (sau mici) sunt în ordine: 'A' are codul 65, 'B' are codul 66, .. , 'Z' are codul 90. Două caractere consecutive în alfabet au coduri ASCII consecutive! De asemenea, litera 'a' are codul 97, etc.
- codurile ASCII ale literelor mici sunt mai mari decât codurile ASCII ale literelor mari ('a' > 'Z') și diferenţa între codurile ASCII a două litere (mică – mare) este 32.
- cifrele au coduri consecutive: caracterul '0' are codul 48, caracterul '1' are codul 49, etc. *Observăm că caracterul '0' nu are codul ASCII 0, ci 48.
- caracterul spaţiu este un caracter imprimabil. Spațiul are codul ASCII 32.
Tabel ASCII